
 Son zamanlarda otomatik öğrenme konusunda düzenli olarak heyecan verici yeni gelişmeler yaşanıyor. Ancak bu gelişmelerin ortaya çıkışı da çok kolay olmuyor. Verilerdeki modelleri tanıması ve öngörmesi adına algoritmalarda gerekli ayarları yapmak için oldukça fazla miktarda daha önceden etiketlenen bilgiye ulaşmak gerekiyor. Google’ın yeni yayınladığı arşivler bu konuda araştırmacıların imdadına yetişecek gibi gözüküyor.
Son zamanlarda otomatik öğrenme konusunda düzenli olarak heyecan verici yeni gelişmeler yaşanıyor. Ancak bu gelişmelerin ortaya çıkışı da çok kolay olmuyor. Verilerdeki modelleri tanıması ve öngörmesi adına algoritmalarda gerekli ayarları yapmak için oldukça fazla miktarda daha önceden etiketlenen bilgiye ulaşmak gerekiyor. Google’ın yeni yayınladığı arşivler bu konuda araştırmacıların imdadına yetişecek gibi gözüküyor.
Open Images ve YouTube8-M adını taşıyan veri tabanları, araştırmacılara otomatik öğrenme süreçlerini iyileştirmeleri için milyonlarca ayrıntılı bağlantı sunacak.
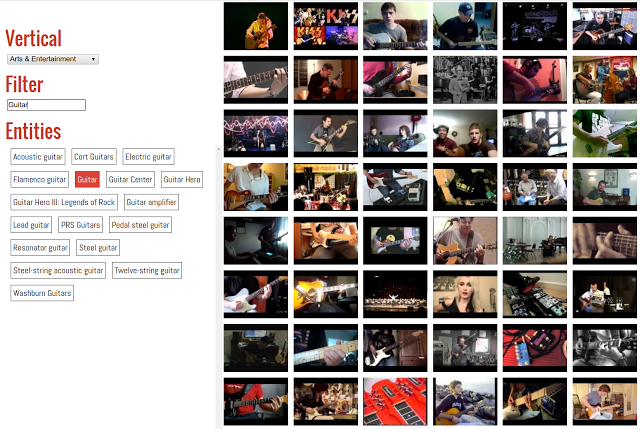 Open Images veri tabanı, Google ile Carnegie Mellon ve Cornell üniversitelerinin işbirliğiyle hazırlandı. Bilgisayarlar tarafından etiketlenen 9 milyon girdi, sonrasında insanlar tarafından kontrol edildi ve doğrulandı. Google Research ekibinden yapılan açıklamada, bu veri tabanındaki görüntülerin bir nöral ağı en baştan eğitmek için yeterli olduğu belirtildi. Open Images ile DeepDream benzeri bir proje hazırlanabilecek.
Open Images veri tabanı, Google ile Carnegie Mellon ve Cornell üniversitelerinin işbirliğiyle hazırlandı. Bilgisayarlar tarafından etiketlenen 9 milyon girdi, sonrasında insanlar tarafından kontrol edildi ve doğrulandı. Google Research ekibinden yapılan açıklamada, bu veri tabanındaki görüntülerin bir nöral ağı en baştan eğitmek için yeterli olduğu belirtildi. Open Images ile DeepDream benzeri bir proje hazırlanabilecek.
Google otomatik öğrenme imkanlarından herkesin faydalanmasını istiyor
YouTube8-M ise toplam süresi 500 bin saatten fazla olan 8 milyon video üzerinden bir veri tabanı sunuyor. Google Research ekibi, YouTube8-M ile mevcut video veri setlerine kıyasla ölçekte ve çeşitlilikte kayda değer bir artış yaşandığına dikkat çekiyor. Şirket, böylelikle büyük veriye ulaşma imkanı olmayanların da video analiz imkanlarından faydalanabilmesini amaçlıyor. Videolardan çok sayıda hareketsiz görüntüyü ayıklayan ve etiketleyen Google, etiketlenmiş bilgilerin araştırmacılar tarafından indirilmesini mümkün kılıyor. Böylelikle yapay zeka tabanlı bir proje geliştirenlerin daha akıllı bir çözüm sunması kolaylaşıyor.
